
- March 1, 2024
- Posted by: Sriramvel M
- Categories: AI/ML, Analytics, Data Analytics, Healthcare Analytics, Hospital Dataanalytics, Python library, Snowflake
Introduction:
In this blog, we aim to investigate the factors influencing patient readmissions to hospitals and how we can take precautions to improve their healthcare outcomes, ultimately reducing mortality rates.
Machine learning models can analyse vast amounts of patient data to identify patterns and trends that may not be immediately apparent to healthcare professionals. This data-driven approach enables more informed decision-making, leading to better patient care and outcomes.
By identifying patients at a higher risk of readmission, healthcare professionals can focus on providing targeted interventions and support to those individuals, potentially preventing unnecessary readmissions.
This model will help for the following reasons,
- Resource Allocation
- Cost Reduction
- Quality of Care Improvement
- Enhanced Patient Experience
- Data-Driven Decision Making
- Compliance and regulations
Snowpark:
Snowpark is a feature in Snowflake, a cloud-based data warehousing platform, designed to enable users to perform advanced data transformations, analytics, and machine learning directly within Snowflake’s environment. Snowpark allows developers to write code in languages like Java or Scala, leveraging familiar tools and libraries, to build data processing pipelines and execute complex computations on data stored in Snowflake. It provides flexibility and scalability for performing data engineering tasks and running custom analytics, enhancing the capabilities of Snowflake as a comprehensive data platform.
Supported Languages:
Snowpark supports languages such as Java, Scala, and Kotlin, offering flexibility for users to leverage their preferred programming language.
User-Defined Functions (UDFs):
Snowpark enables the creation of custom User-Defined Functions (UDFs) in Java, Scala, or Kotlin.
These UDFs can be applied to process and transform data stored in Snowflake.
Integration with Snowflake:
Snowpark is tightly integrated with Snowflake, allowing users to execute custom code directly within the Snowflake environment.
This integration ensures seamless data processing and analytics capabilities.
Data Processing and Transformation:
Users can perform advanced data processing and transformation tasks using Snowpark, enhancing the capabilities of Snowflake for complex use cases.
Machine Learning Integration:
Snowpark can be leveraged for machine learning tasks within Snowflake, enabling data scientists to use programming languages for data preparation, feature engineering, and model integration.
Real-time Data Processing:
Snowpark facilitates real-time data processing, allowing users to apply custom logic to incoming data streams within the Snowflake platform.
Collaborative Environment:
Snowpark provides a collaborative environment for data engineers and data scientists to work together, with data processing and analytics capabilities accessible within Snowflake.
Prerequisites:
- A snowflake account with valid credentials and connection.
- A python environment with necessary libraries installed. In our case we use VS Code.
Step 1: Import of libraries:
- Necessary libraries including Snowpark should be imported into VS Code or any IDE of your choice as shown below
Step 2: Connect Snowpark Account with VS Code:
- Connect your snowflake database with your python environment by creating a Snowpark session.
Step 3: Import of Data from Snowflake:
- Once the Snowpark connectivity is established, retrieve necessary data using SQL query from the snowflake database.
(Here, the readmission data is stored in the “DATA” table)

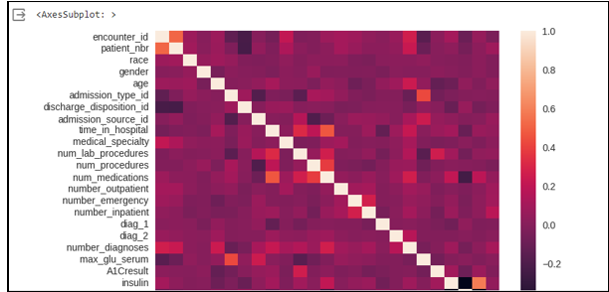
Step 4: EDA:
Correlation heatmap:
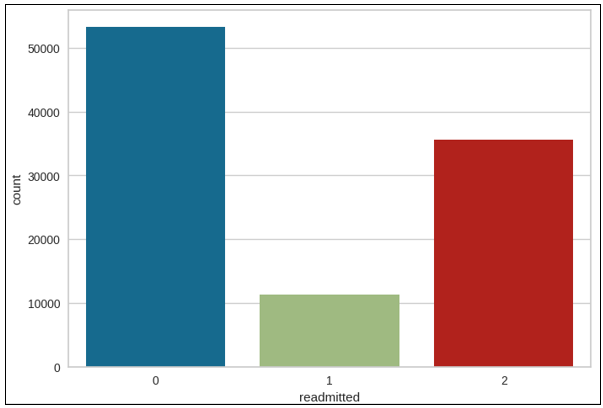
Count plot:
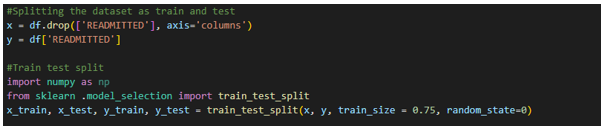
Step 5: Train Test Split:
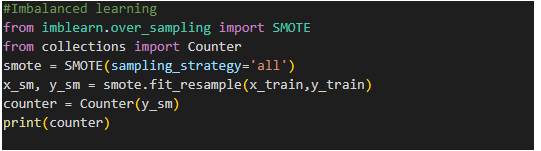
Step 6: Imbalanced learning:
- As mentioned in the count plot that our dependent variable subclasses are not balanced. Imbalanced learning is used to balance those classes by using the SMOTE technique.
(SMOTE stands for Synthetic Minority Over-sampling Technique. It is a technique used in the field of machine learning and data mining to address the class imbalance problem. SMOTE works by generating synthetic examples of the minority class to balance the class distribution. It does this by creating new instances of minority class samples by interpolating between existing minority class samples. This helps to create a more balanced dataset, which can improve the performance of machine learning models, especially in cases where the class imbalance is severe)
Step 7: Model Building:
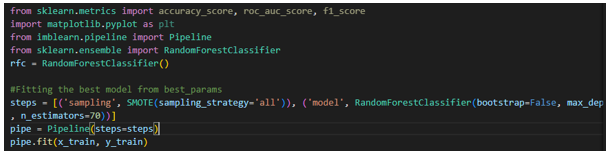
Step 8: Feature Importance and confusion matrix:
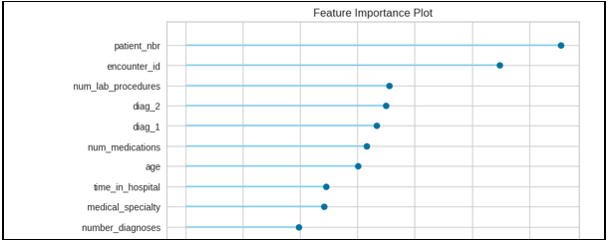
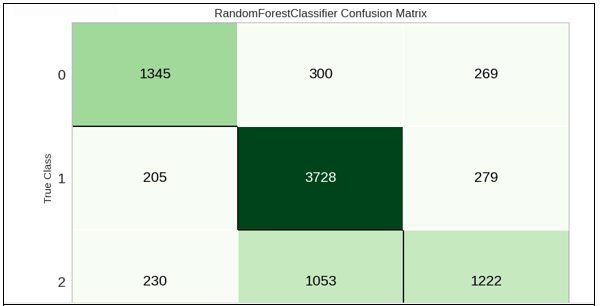
Conclusion:
Hospital readmissions pose a significant challenge for healthcare providers, both in terms of patient care and resource allocation. Hospital readmission prediction with Snowpark involves utilizing Snowflake’s Snowpark feature to analyze healthcare data and forecast the probability of patients being readmitted to the hospital.
Snowpark empowers developers to conduct advanced data transformations, analytics, and machine learning to examine historical patient data to identify trends and factors linked to hospital readmissions. This approach enables healthcare providers to take proactive steps to enhance patient care, lower readmission rates, and optimize resource allocation within the hospital environment.
Please feel free to reach out to us to discuss how we can address your needs in the AI/ML space. We offer customized solutions designed to effectively meet your specific requirements.