
- July 8, 2019
- Posted by: Gautham Krishnamoorthy
- Categories: Cloud Datawarehouse, Next Gen Analytics, Power BI, Technology
Introduction to Incorta
Incorta aggregates complex business data in real-time, eliminating the need to reshape it. With the industry’s first Direct Data Mapping architecture, Incorta provides unprecedented join performance–making the data warehouse obsolete. Incorta accelerates the time required to roll out new analytic applications from months to days and reduces query and reporting times from minutes to seconds. Also, It can also be linked to multiple third party apps such as (PowerBI, Tableau ..) for extensive reporting.
Please find our blog on Instantaneous Reporting with Incorta.
Incorta Architecture
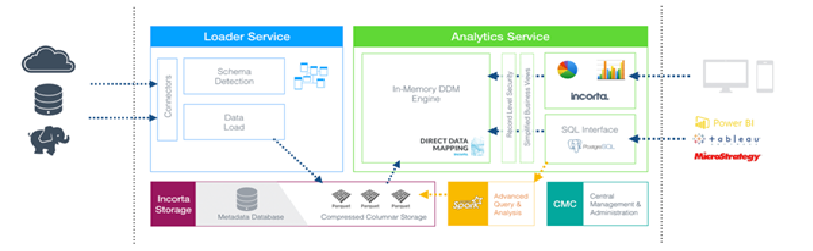
Using Spark, Incorta also uses materialized views. In this instance, Spark reads the staging Parquet, executes the transformation and then loads the materialized view to a different Parquet instance. The loader accesses the materialized view and loads the analytics engine for output.
Materialized Views and Spark
A Materialized View in Incorta is an object type that contains the results from an advanced transformation program. They are derived or engineered tables that bring life to the Incorta Spark layer and provide endless opportunities to handle complex data transformation / use cases. The materialized view can be scheduled to load periodically like any other Incorta object.
Once the materialized view is populated, it can be used like another object. You can define aliases, joins, and define formula columns. You can query the materialized view in an Insight, and you can define a business schema using a materialized view.
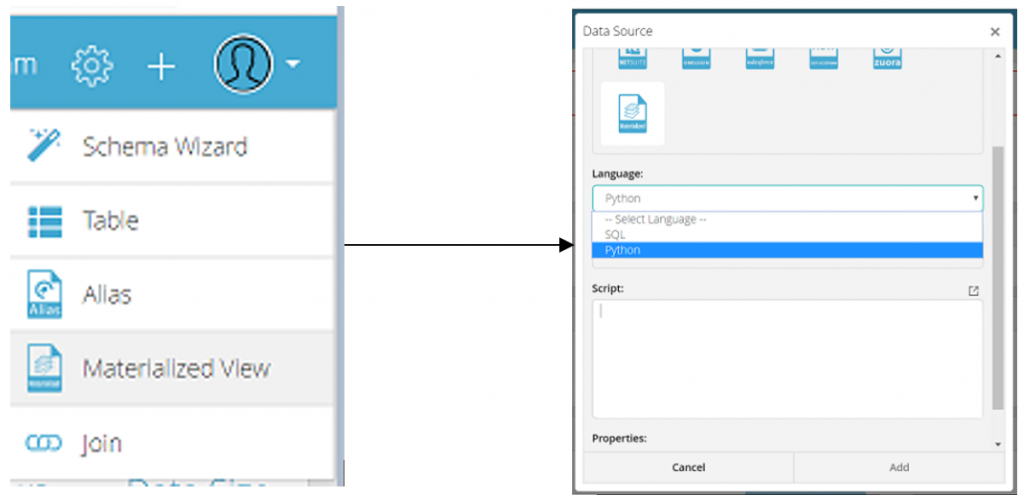
Creating Materialized View
Go to Schema -> Add -> Materialized View
You can choose either SQL or Python depending upon your use case complexity.
Using Python:
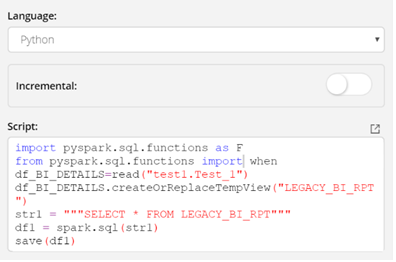
Read (), Save () functions are associated with python based MV. This type can be used when complex transformations, data quality analysis or machine learning are involved.
If you receive an error message regarding missing Python libraries or modules you may need to install new libraries/modules.

Using SQL:
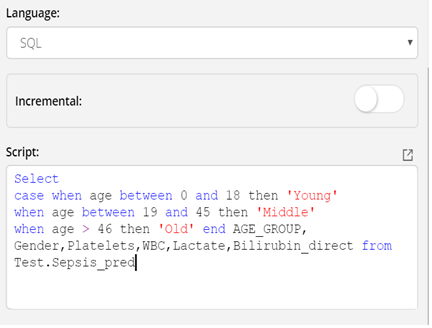
Use the language as SQL if there is only query for which you need to create a MV.
Connecting Spark Master Web UI
The Spark Master URL can be found from either the Incorta Admin UI (ie. http://<server>:<port>/incorta/admin) or from the Spark Master Web UI (which is usually http://<server>:9091)
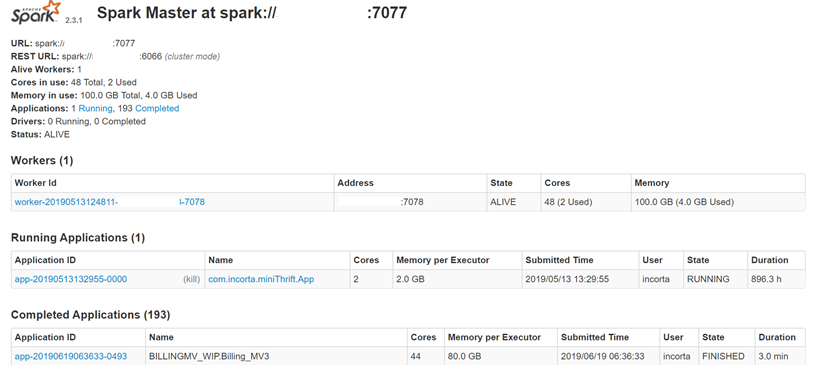
Spark Configurations
Cores in use – Total number of cores available
Memory in use – Total size of memory available
Status – Name of job, Job running status (Running / Completed), Duration of job, User, Number of cores used, Memory per Executor utilized
Important properties in Spark MV
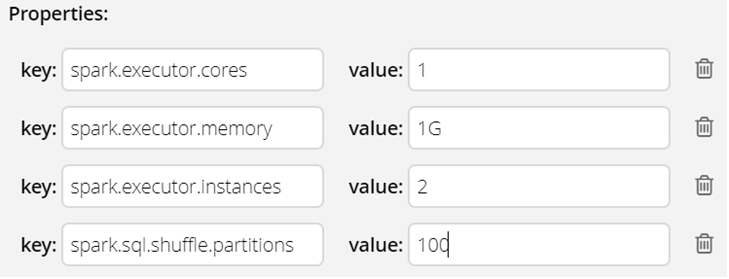
spark.sql.shuffle.partitions
Default:200
Depending on your use case, this can be beneficial or harmful. In this case, one can see that the data volume is not enough to fill all the partitions when there are 200 of them, which causes unnecessary map reduce operations, and ultimately causes the creation of very small files in HDFS, which is not desirable. If however you have too little partitions, and lots of data to process, each of your executors memory might not be enough/available to process so much at one given time, causing errors like this java.lang.OutOfMemoryError: Java heap space. Remember that each partition is a unit of processing in Spark.
spark.executor.memory
Default:1G
Amount of memory to use per executor process. The memory property impacts the amount of data Spark can cache, as well as the maximum sizes of the shuffle data structures used for grouping, aggregations, and joins.
- Running executors with too much memory often results in excessive garbage collection delays.
- Running tiny executors (with a single core and just enough memory needed to run a single task, for example) throws away the benefits that come from running multiple tasks in a single JVM.
If number of cores or memory exceeds the availability it will be in waiting state until the resources are freed.
spark.executor.cores
Default:8
The number of cores to use on each executor. The cores property controls the number of concurrent tasks an executor can run. –executor-cores 5 means that each executor can run a maximum of five tasks at the same time.
spark.executor.instances
Default:1
The number of executors for static allocation. Number of executors in the node for a job.
It is not necessary to add these properties for all MV’s creation. Default properties are very much capable of taking bulk loads (Few GB’s). You can fine tune the performance of the job using spark properties.
In the next blog we will cover the PySpark ML use case. Please feel free to reach Cittabase for more information.