
- March 6, 2024
- Posted by: Arvind Nagarajan
- Categories:

Auto Loader is a feature in Databricks to stream or incrementally ingest millions of files per hour from data lake storage. Autoloader provides a Structured Streaming source called cloudFiles. It can be used to process billions of files to migrate or backfill a table. Auto Loader scales to support near real-time ingestion of millions of files per hour.
In this blog, we will delve into the mechanisms and advantages of Databricks Autoloader.
Let us take a scenario where there are couple of csv’s to be uploaded / ingested to a delta table. This can be achieved through a pre-built batch load process. The problem shows up when a new set of csv’s/or other files comes in. It will be challenging to continue the process of ingestion as it will be hard to keep tabs on which files to ingest and which was read already.
We will investigate some rules for any efficient data ingestion process.
- Need to read only new files.
- No files should be missed.
- Need for flexibility over the trigger process (Either immediate or batch)
- Repeatable / Reusable process.
- Speed of execution
Existing ETL patterns for ingestion:
Using metadata driven process. – For example, manually keeping track of file through a process and loading the last uploaded/updated file. This will prove hard when managing the trigger process and locating or inferring schema and adapting to the changes in the metadata.
Spark file streaming. Spark reads entire directory structure and compares it with the files that were read previously and load any file that was not present in either structure. This will start to slow down as more and more files come in.
Custom data ingestion using cloud tools and structure.
Now, we will look at the Autoloader specifics for achieving this:
Implementing Autoloader in Databricks:
There are two parts to the autoloader job:
- CloudFiles DataReader
- CloudNotification services (Optional)
Default dataframe syntax:
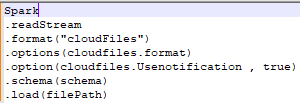
We will review the autoloader implementation specifics below.
Approach:
We will get the autoloader feature running with an example. We will be parking a file in the blob storage and see how autoloader streams all incoming files.
- Setup a notebook in Databricks.
- Since autoloader needs to have a base schema structure for the incoming file, we will be storing the schema info as parameters.
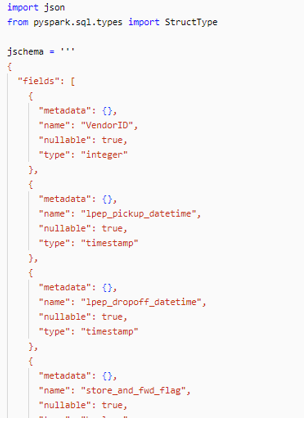
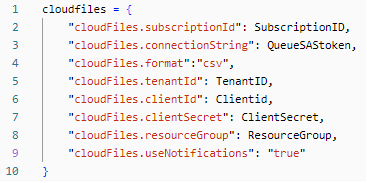
3. Call all necessary Lakehouse secrets and parameters

4. Store all the required autoloader parameters.
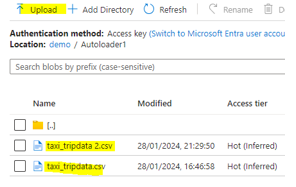
5. Connect to the blob storage using spark config,

6. Add files to the blob storage container,
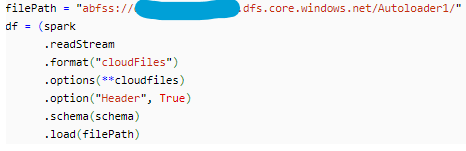
7. Invoke autoloader read stream by using “cloudFiles” in the spark data frame format. Describe the file path as well.
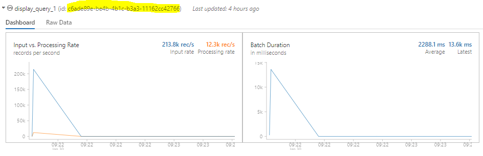
8. Now, we will monitor how the data is streamed via autoloader,
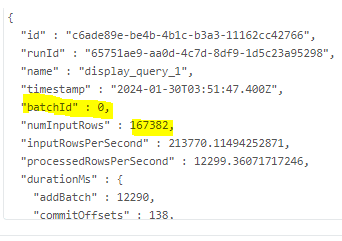
9. We will check the count of the rows in both the files
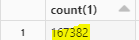
This matches with number of input rows returned while streaming.
Note that if needed we can view events and storage queue via Azure UI under “events” menu in the container.
Updating Records
Here we will investigate how the records get updated through Autoloader stream.
- Carry out all the steps until 5 described in the default approach.
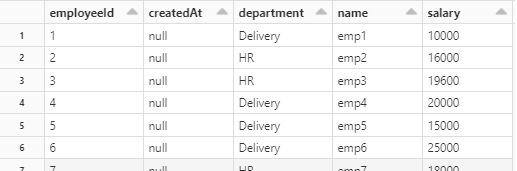
- Here’s how Employee 1 table looks like.
3.We merge the below table with the above table with all existing records (if changed) updated, and new records if available will be added.

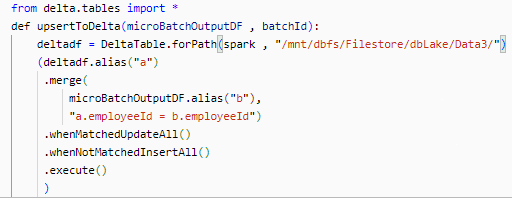
4.We will furnish a function to check if there are any updates in the incoming file and carry those changes to the landing file.
5. Invoke Autoloader and monitor the results.
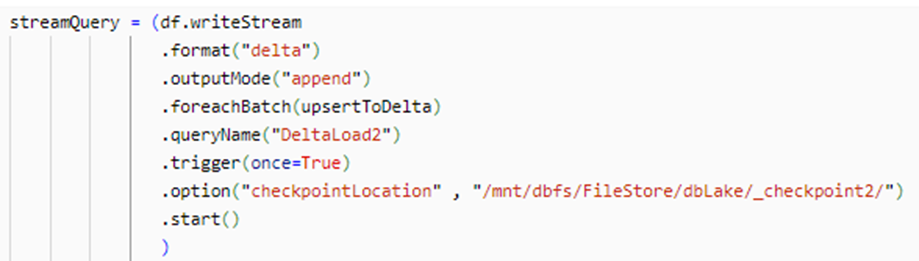
6.Note for each batch we are calling the function to handle updates to the file, and we are triggering only once to reduce compute costs.
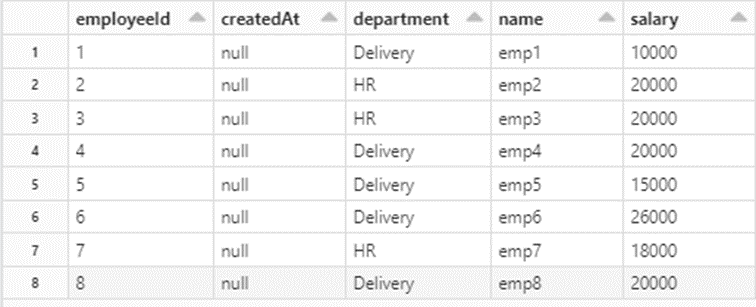
We can see that the table has been updated.
Conclusion
With Autoloader, organizations can harness the power of streaming data to drive actionable insights and informed decision-making. Whether you’re processing IoT data, analyzing log files, or performing real-time analytics, Autoloader in Databricks provides a flexible and scalable solution for streaming data processing in the cloud.
Please contact us for your Databricks solution requirements. Our solutions include a comprehensive range of services tailored to address your data integration and migration requirements.