
- May 29, 2024
- Posted by: Anisha P
- Category: Snowflake
Introduction:
Snowpark, a powerful Python SDK for Snowflake, offers a seamless way to ingest data into Snowflake databases. By leveraging the Snowpark Session class and the SnowflakeFile utility, you can efficiently read, transform, and load data from various sources, including CSV files, into Snowflake tables.
Load data into stage:
Create a named internal stage and upload the file that must be loaded into Snowflake.
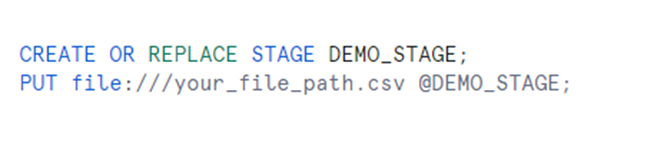
Using SnowflakeFile:
Snowpark file access enables secure, programmatic access to files in either internal or external Snowflake stages from within Snowpark User-Defined Functions (UDFs), User-Defined Table Functions (UDTFs), or Stored Procedures.
The script provided demonstrates a Snowflake stored procedure that automates the process of ingesting data from a CSV file. The procedure utilizes Snowpark’s capabilities to read the file, perform data transformations (such as removing null values and deduplicating the data), and then write the processed data directly to a Snowflake table.
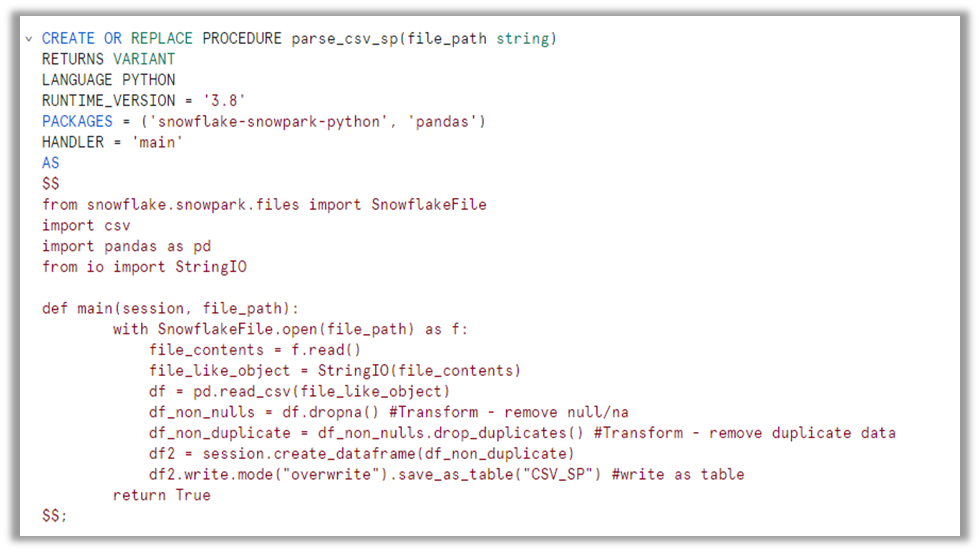
Procedure Implementation:
It takes two parameters: session (a Snowpark session object) and file_path (the input file path).
The function uses the SnowflakeFile.open() method to read the contents of the CSV file specified by the file_path.
The file contents are read and converted to a Pandas DataFrame using pd.read_csv().
The DataFrame is then transformed by removing null/NA values using df.dropna() and removing duplicate rows using df.drop_duplicates().
The transformed DataFrame is then converted to a Snowpark DataFrame using session.create_dataframe().
Finally, the Snowpark DataFrame is written to a Snowflake table named CSV_SP using the write.mode(“overwrite”).save_as_table() method.
Procedure Execution:

The script calls the PARSE_CSV_SP procedure, passing the file path build_scoped_file_url(@DEMO_STAGE, ‘snowpark_file_ingest_blog1.csv’) as the argument.
Data Retrieval:
The script concludes by selecting all the data from the CSV_SP table, which was created by the stored procedure.

Using Snowflake Session:
The Session class in Snowpark serves as the entry point for interacting with data and executing computations within a Snowpark environment.
import snowflake.snowpark as snowpark
from snowflake.snowpark.functions import col
from snowflake.snowpark import Session
from snowflake.snowpark.types import IntegerType, StringType, StructField, StructType, DateType ,FloatType
import json
import pandas as pd
with open (f"C:\\Users\\Downloads\\snowflake_config.json") as f:
config_file = json.load(f)
connection_string = config_file['connection_parameters']
session = Session.builder.configs(connection_string).create()
schema = StructType(
[StructField("Customer_ID" ,IntegerType()),
StructField("First_Name", StringType()),
StructField("Email", StringType()),
StructField("Default_Address_Company", StringType()),
StructField("Default_Address_Address1", StringType()),
StructField("Default_Address_Country_Code", StringType()),
StructField("Phone", StringType()),
StructField("Total_Spent", FloatType()),
StructField("Total_Orders", IntegerType()),
StructField("Note", StringType()),
StructField("Tags", StringType()),
StructField("UPDATED_AT", StringType())
])
#Use the DataFrameReader (session.read) to read from a CSV file
df_cust = session.read.schema(schema).options({"field_delimiter": ",", "skip_header": 1}).csv('@DEMO_STAGE/Customer_details_01.csv')
len1 = df_cust.count()
print("full records: ", len1)
# Remove empty columns
df_remove_col = df_cust.drop("Default_Address_Company", "Note")
# drop a row if it contains any nulls, with checking column "Customer_ID"
df_non_null = df_remove_col.na.drop(subset=["Customer_ID"])
len2 = df_non_null.count()
print("full records df_non_null: ", len2)
# #Remove all duplicate
df_non_duplicate = df_non_null.dropDuplicates("Customer_ID")
df_non_duplicate.show()
len3 = df_non_duplicate.count()
print("full records df_non_duplicate: ", len3)
#Filter data
filtered_df = df_non_duplicate.filter(col("Tags").startswith("egnition"))
filtered_df.show()
len4 = filtered_df.count()
print("full recordsfiltered_df: ", len4)
copied_into_result = filtered_df.write.mode("overwrite").save_as_table("Cust_details")
A breakdown of the script’s functionality:
Loading Configuration: The script starts by loading a JSON file containing Snowflake connection parameters. These parameters are used to establish a connection to the Snowflake database.
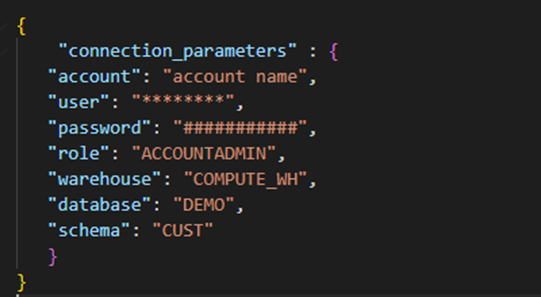
Creating a Snowflake Session: The script uses the connection parameters to create a Snowflake session using Snowpark’s Session class.
Defining the Schema: The script defines a schema for the data to be loaded. This schema includes fields such as “Customer_ID”, “First_Name”, “Email”, and others, along with their corresponding data types.
Loading Data from CSV: Snowpark’s DataFrameReader is used to load data from a CSV file named “Customer_details_01.csv” located in a Snowflake stage named ‘@DEMO_STAGE’. The data is loaded into a DataFrame named df_cust.
Data Transformation: It performs several operations on the data:
Removing Empty Columns: It drops columns with empty values from the DataFrame.
Removing Rows with Nulls: It drops rows from the DataFrame if they contain any null values, specifically checking the “Customer_ID” column.
Removing Duplicates: It removes duplicate rows from the DataFrame based on the “Customer_ID” column.
Filtering Data: It filters the DataFrame to include only rows where the “Tags” column starts with “egnition”.
Saving Data to Snowflake Table: The script writes the filtered DataFrame to a Snowflake table named “Cust_details” using the write method. The mode(“overwrite”) option ensures that any existing data in the table is overwritten with the new data.
Conclusion:
By Implementing this Snowpark-based data ingestion approaches, the data of various formats (CSV, JSON, XLSX, PARQUET) can be loaded from Snowflake stage to Snowflake database seamlessly.
Cittabase is a select partner with Snowflake. Please feel free to contact us regarding your Snowflake solution needs. Our snowflake solutions encompass a suite of services for your data integration and migration needs. We are committed to providing personalized assistance and support customized to your requirements.